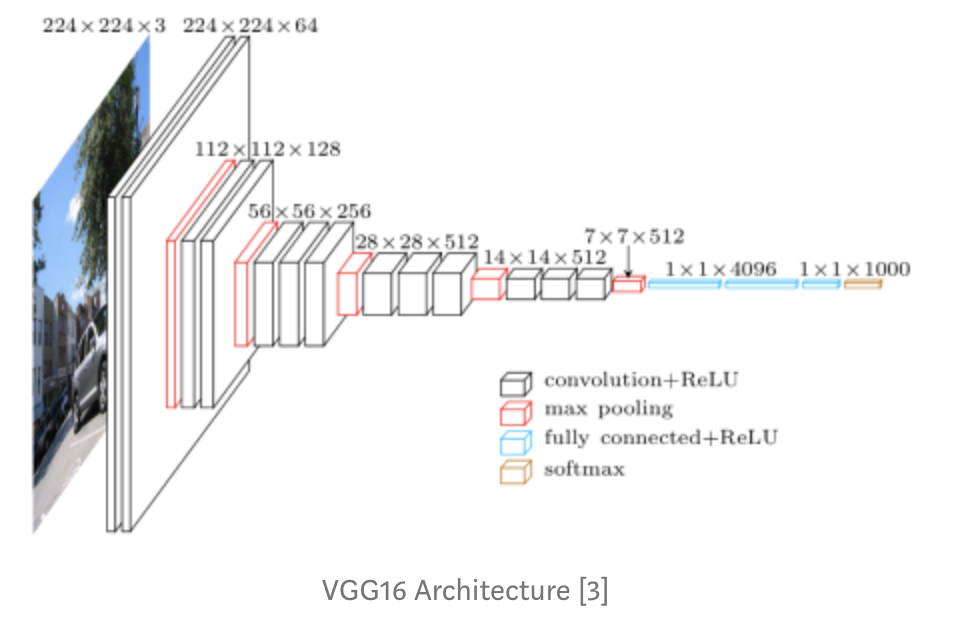
포스팅을 한지 시간이 제법 지났네요. 이제 VGGNet에 대해 이야기를 할 두번 째 시간입니다. 먼저 그림부터 살짝 보고 가세요.
VGG_Details
2014년에는 크게 다른 두 가지 아키텍쳐가 있었고 성능이 크게 향상되었어요. 이 차이점은 네트워크의 깊이가 깊을 수록 심했다고 합니다.(아마 성능차이가 메인이였을 거에요. 연산량 역시 19가 훨씬 많았을거구요.)
VGG 16은 16개의 층을 가진 아키텍쳐 입니다. 2개의 Conv 레이어와 풀링레이어 그리고 마지막에는 fully connected 레이어까지요. VGG 네트워크가 갖고 있는 아이디어는 더더더 깊어진 네트워크 그리고 그와 함께 더더 적은 필터들 입니다. VGGNet은 8개의 층을 가진 AlexNet과 비교했을 때 layer의 수를 늘렸습니다. 지금 현재 VGG는 16~19의 layer 변형 모델이 있죠. 한가지 주목 해야할 점은 이러한 모델이 3x3의 작은 필터 사이즈를 유지한다는 것입니다. 기본적으로 이것은 인접한 픽셀을 아주아주 조금만 참고하게 되는 가장 작은 필터 사이즈입니다. (3x3이란 것이 말이에요) 그리고 요 VGG는 말이죠. 네트워크를 통해서 주기적으로 풀링을 해주며 3x3 conv의 간단한 구조를 유지했습니다.
VGGNet에는 몇개의 더 많은 conv layer, pooling layer, 더 많은 conv layer 등등 정리해서 conv layer와 pooling layer가 있습니다. VGG Architecture에는 총 16개의 conv 및 fully connected layer가 있습니다. VGG 16의 경우 16개가 있는거구요. VGG 19의 경우 19가 있고 이 VGG19의 경우 매우 유사한 형태를 갖지만 몇개의 conv layer가 더 있다는 점에서 차이점을 갖게 됩니다.
parameter
그래서!! 위의 그림에서 보시다시피.(위의 그림은 해석하면서 보세요. 따로 설명 안할게요) 총 138M의 총 파라미터와 각 이미지가 96MB(일반 이미지 보다 훨씬 커요!)를 잡아 먹게 되어 계산 비용이 아주 많이 들게 되는 것이죠. 참고로 ILSVRC 대회에서 7.3의 오류율을 기록했습니다.
VGGNet은 2014년 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)에서 선두주자였습니다.
알렉스넷은 최초로 제안된 거대한 크기의 CNN(convolutional neural network) 아키텍쳐에요. 그리고 이 알렉스넷은 ImageNet classification이라는 대회에서 꽤 잘 먹혔죠.
알렉스넷은 대회에서 쓰이게 되며 딥러닝방식이 아닌 다른 모델들을 큰 격차로 눌렀어요.
알렉스넷의 구조는 Pooling layer, Normalization, conv-pool-norm 그리고 몇개의 conv layer, pooling layer 그리고 이후로 몇개의 fully connected layer가 뒤에 붙는 Conv Layer입니다. 실제로 이건 "LeNet Network"와 아주아주 비슷하게 보이죠? 전체적으로 단순히 몇개의 층이 더 있을 뿐이죠. 이 conv layer 중 5개 그리고 최종적으로 연결된 레이어가 출력 클래스로 가기 전에 2개의 fully connected layer가 있어요.
알렉스넷은 ImageNet에서 훈련되었으며, 입력은 227x227x3의 사이즈를 가진 이미지들이 사용되었어요. (지금부턴 바로 위의 그림 "AlexNet Layers Details[2]" 를 보면서 따라오세요) AlexNet의 첫번째 레이어를 봐바요. 첫번째 레이어는 Conv Layer에요. 그리고 이 첫번째 layer는 11x11 사이즈의 filter이구요, 그 필터는 96개가 있다고 해요. 그 필터들은 stride가 4로 설정되어 있어요. 그렇게 해서 output으로 우린 55x55x96 을 얻었어요. 그리고 35K개의 파라미터들을 첫번째 레이어에서 얻었어요.
그림을 보면 두번째 Layer는 Pooling Layer에요. 이 때 우린 총3개의 필터를 갖고 있어요. 이 때 필터는 3x3사이즈를 갖고 있고 stride는 2로 설정되어 있어요. Pooling Layer의 결과값 크기는 27x27x96 이죠. 학습할 파라미터는 아무것도 없습니다. 0개죠. 아니 왜죠?? 라고 말 할 수 있는데 답은 간단합니다. 파라미터들은 가중치이기 때문이죠. 가중치는 계속해서 배우려고 하는거죠. Convolutional Layer는 우리가 배우게 해야하는 파라미터들을 가지고 있지만 Pooling Layer에서 하는 것은 전부 다 규칙으로 우리가 정해놓았죠. pooling을 해야하는 영역에 대해 거기서 최대값을 가져오는거죠. 그래서 우리가 학습해야할 파라미터가 아무것도 없는 것죠.
처음에 11x11의 필터가 있고, 5x5 필터도 있고 3x3 필터도 있어요. 끝에는 우린 4096사이즈의 fully connected layer가 2개 있어요. 끝에는 FC1000이 Softmax로 들어가죠. Softmax는 1000개의 ImageNet클래스들과 연결이 됩니다. 이 아키텍쳐는 ReLu의 최초 사용이에요!(ReLU를 처음으로 사용했다는 점에서 중요하다고 하더라구요)
하이퍼파라미터 :
이 아키텍쳐(설계)는 ReLU의 비선형성을 최초로 사용했어요. AlexNet은 Normalization(정규화) 레이어 역시 사용했어요. Data Augmentation로는 AlexNet에서는 flipping, jittering, cropping,colour 정규화 등등을 사용했다고 논문에 나와요. 다른 파라미터들로는 Dropout은 0.5를 줬고, SGD + Momentum으로는 0.9를 줬구요. 처음에 학습속도(Learning Rate)로는 1e-2(0.01)를 줬다고 합니다. Validation 정확도가 변화가 없어질 시점이 되면 10배 정도 더 감소시켰다고 해요. 이 알렉스넷 Regularization에 사용된 것은 L2를 사용했고 L2에는 5e-4의 Weight Decay를 썼다고 합니다. 그리고 3GB의 메모리를 가진GTX580 GPU에서 학습했다고 합니다.
최종적으로 알렉스넷은 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)에서 16.4%의 오류율을 달성하는 성과를 냈다고 합니다.