AlexNet, VGGNet, ResNet, Inception, DenseNet의 아키텍쳐 (2)
포스팅을 한지 시간이 제법 지났네요. 이제 VGGNet에 대해 이야기를 할 두번 째 시간입니다. 먼저 그림부터 살짝 보고 가세요.
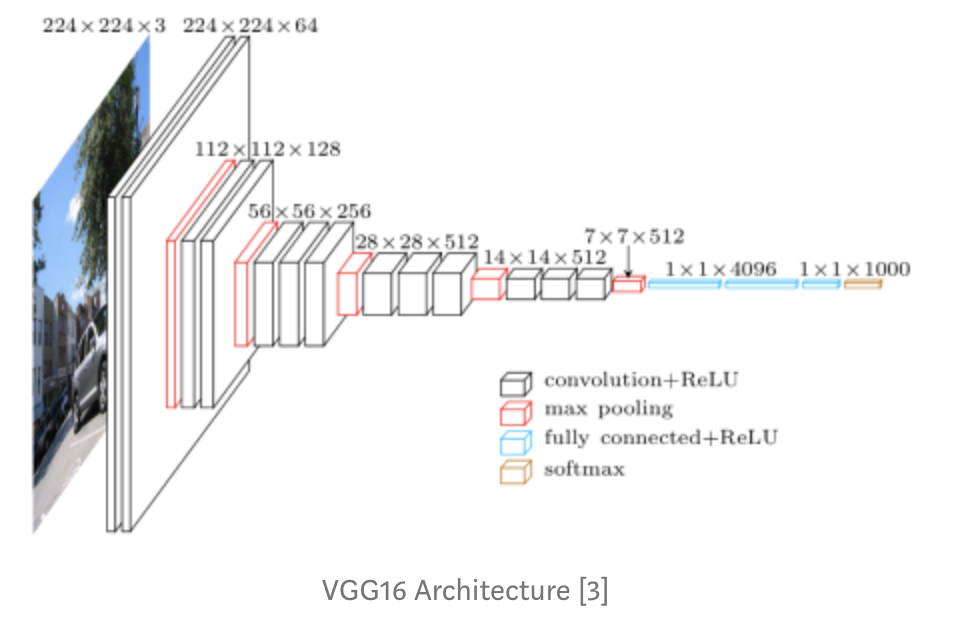

2014년에는 크게 다른 두 가지 아키텍쳐가 있었고 성능이 크게 향상되었어요. 이 차이점은 네트워크의 깊이가 깊을 수록 심했다고 합니다.(아마 성능차이가 메인이였을 거에요. 연산량 역시 19가 훨씬 많았을거구요.)
VGG 16은 16개의 층을 가진 아키텍쳐 입니다. 2개의 Conv 레이어와 풀링레이어 그리고 마지막에는 fully connected 레이어까지요. VGG 네트워크가 갖고 있는 아이디어는 더더더 깊어진 네트워크 그리고 그와 함께 더더 적은 필터들 입니다. VGGNet은 8개의 층을 가진 AlexNet과 비교했을 때 layer의 수를 늘렸습니다. 지금 현재 VGG는 16~19의 layer 변형 모델이 있죠. 한가지 주목 해야할 점은 이러한 모델이 3x3의 작은 필터 사이즈를 유지한다는 것입니다. 기본적으로 이것은 인접한 픽셀을 아주아주 조금만 참고하게 되는 가장 작은 필터 사이즈입니다. (3x3이란 것이 말이에요) 그리고 요 VGG는 말이죠. 네트워크를 통해서 주기적으로 풀링을 해주며 3x3 conv의 간단한 구조를 유지했습니다.
VGGNet에는 몇개의 더 많은 conv layer, pooling layer, 더 많은 conv layer 등등 정리해서 conv layer와 pooling layer가 있습니다. VGG Architecture에는 총 16개의 conv 및 fully connected layer가 있습니다. VGG 16의 경우 16개가 있는거구요. VGG 19의 경우 19가 있고 이 VGG19의 경우 매우 유사한 형태를 갖지만 몇개의 conv layer가 더 있다는 점에서 차이점을 갖게 됩니다.

그래서!! 위의 그림에서 보시다시피.(위의 그림은 해석하면서 보세요. 따로 설명 안할게요) 총 138M의 총 파라미터와 각 이미지가 96MB(일반 이미지 보다 훨씬 커요!)를 잡아 먹게 되어 계산 비용이 아주 많이 들게 되는 것이죠. 참고로 ILSVRC 대회에서 7.3의 오류율을 기록했습니다.
VGGNet은 2014년 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)에서 선두주자였습니다.
다음 글은 ResNet에 대한 리뷰입니다.